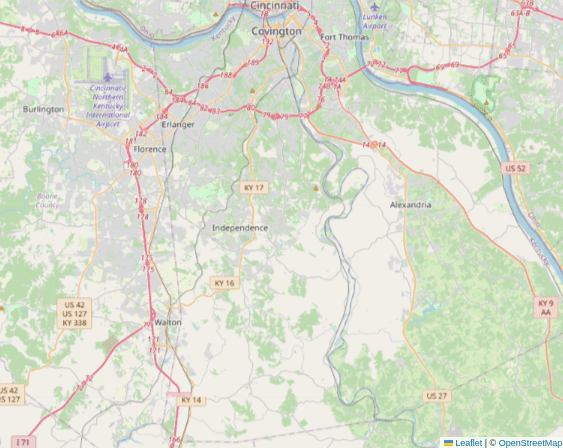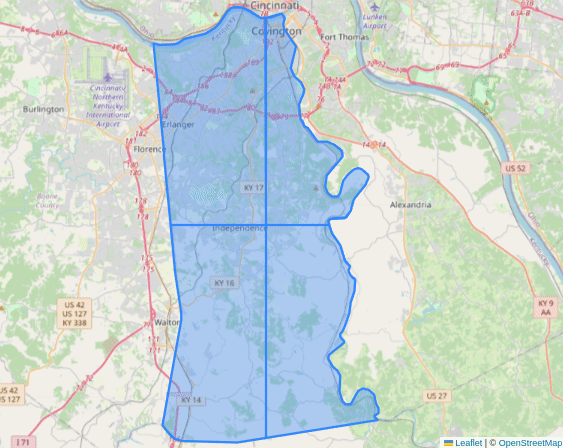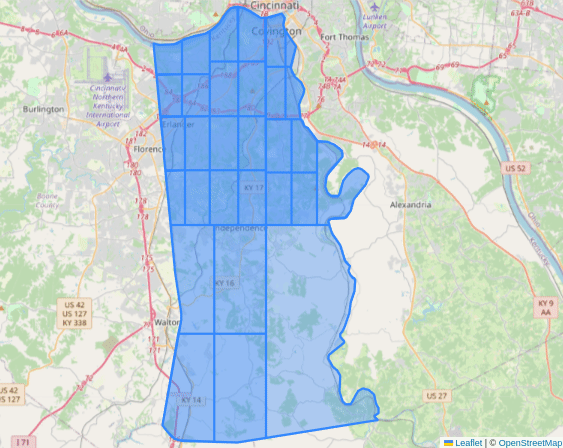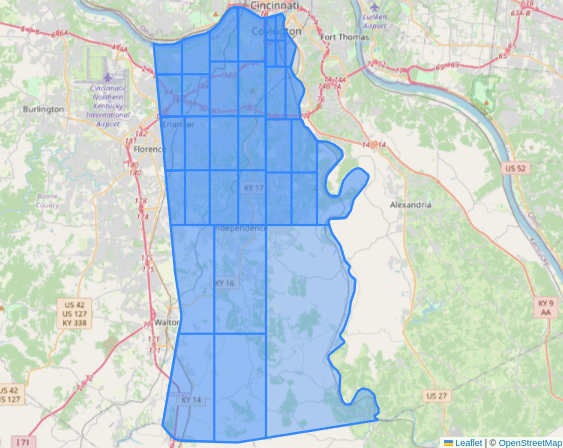
Collecting Locations
Collection is the term used within CostQuest APIs to identify data that falls within a geographic boundary. To do this for Fabric locations, a recursive approach is used to split boundaries into smaller polygons to retrieve complete data for large areas. The PyTools library provides a prebuilt function to do this and is the recommended method.
Problem Statements
- The
fabric/collect2API limits its responses to a maximum number of records. - How is it possible to query increasingly larger areas and know that all of the locations have been identified?
- There are two levers to operate: (1) limit the size of the boundary or (2) limit the number of items returned.
- Pagination isn’t directly available. This would require that the system knows the full result set of data from a geographic operation that may have a valid return of millions of records.
The solution provided follows continuations for areas which would exceed the response size for an individual call.
Algorithm Approach and Description
- Utilize a quadtree approach to divide boundaries if they return too many locations.
- Quadtrees are a common basic spatial index that work well for dividing areas and are easily understood and visualized.
- https://en.wikipedia.org/wiki/Quadtree
- Call
fabric/collect2and if it returns no continuations, add data to a collection. Otherwise,fabric/collect2for the continuations.
Pros and Cons
- Pros
- Avoids long running queries that consume large amounts of resources.
- By controlling the number of returned locations in
fabric/collect2it guarantees a faster response time. So much that the “wasted” calls that then require division are somewhat meaningless in terms of the over all response time. - Avoids constant concern or worry about whether a return is fast enough.
- By controlling the number of returned locations in
- Facilitates distribution of load. One large geospatial query would be run on a single node whereas many smaller
collect2operations can run anywhere. - Allows rate limits to more meaningfully represent the size and complexity of a request. If one call took 20 minutes to run, it should not be treated the same as one that takes 20 milliseconds. Using smaller requests help make rate limiting more logical.
- Avoids long running queries that consume large amounts of resources.
- Cons
- Pushes responsibility for managing operations onto implementations.
- Requires client-side resources for transactions and aggregation of results.
Visualization